1.hashmap简介:
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
2.hashmap实现原理:
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
2.1.hashmap中的put方法:
put元素时首先根据key的hash值和equals方法找到是否有完全一样的key对象,若有,则替换原有的旧值并返回旧值,若无,则新增一个Entry对象放在table[i]处,如果原table[i]处存在元素,则将新增的Entry对象放置在链表头,通过next指向原有的Entry对象,形成链表结构。
2.2.hashmap中的get方法:
首先计算出key的hash值,根据hash值计算出元素存放的bucket位置,如果元素的hash值相同,代表存放的bucket位置相同,由于链表存放的是键值对对象,此时再根据key的equals方法,遍历链表,找到相同的键值对对象,并返回值。
3.hash碰撞
前述说如果key的hash值相同,即key的hashcode相同,此时元素存放的bucket位置相同,这就会导致hash碰撞,hashmap采用数组+链表的结构来解决hash碰撞,虽然key的hashcode相同(暂时记为1),但是不一定equals,遇到hashcode相同的情况,由于hashmap底层的Entry对象有一个很重要的属性next,那么此时如果原来bucket位置存在元素A,记为Entry[1]=A,当元素B进来的时候,此时记B.next=A,Entry[1]=B,当元素C进来时,此时记C.next=B,Entry[1]=C,以此类推。也就是说新增的元素会存放在链表头,通过新元素的next指向原有的元素。这就形成链表,进而解决hash碰撞。
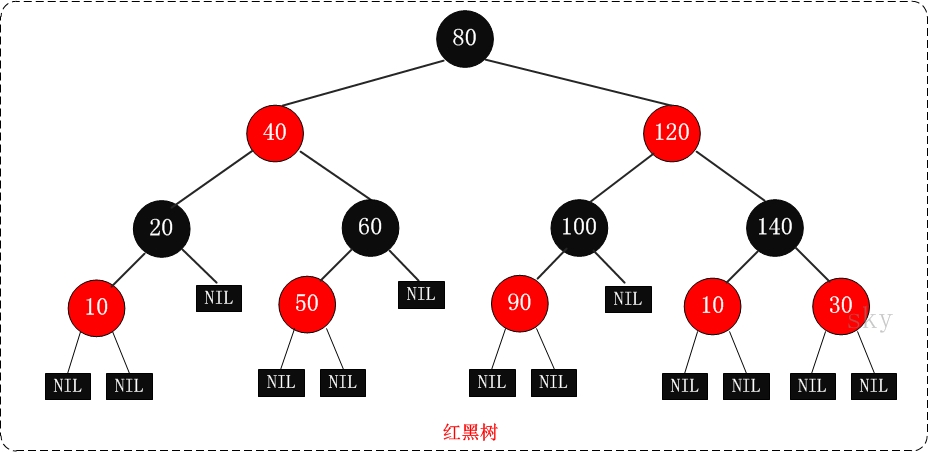
注:在JDK1.8中,解决hash碰撞用到了红黑树的数据结构,当链表长度超过8时,链表会自动转换为红黑树,下面附上红黑树的五个基本特性:
1.所有节点要么是黑色,要么是白色。
2.根节点永远是黑色。
3.所有叶子节点都是黑色的(这儿的叶子节点只NIL节点)。
4.每个红色节点的两个子节点一定都是黑色的。
5.从任意一个节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。